2.3 Stemming
The post explains stemming and shows the implementation of Porter stemmer and snowball stemmer in NLTK
Stemming is the process of removing a part of a word, or reducing a word to its stem or root.
One of the most common - and effective - stemming tools is Porter's Algorithm developed by Martin Porter in 1980. The algorithm employs five phases of word reduction, each with its own set of mapping rules. In the first phase, simple suffix mapping rules are defined, such as:
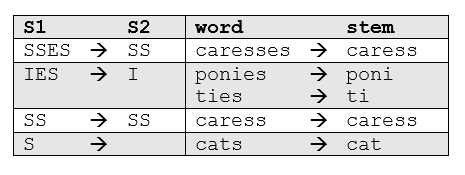
From a given set of stemming rules only one rule is applied, based on the longest suffix S1. Thus, caresses reduces to caress but not cares.
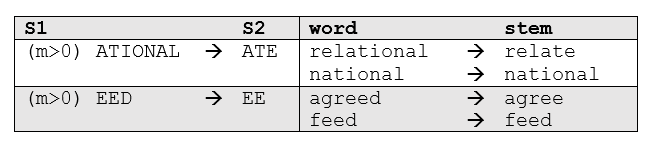
More sophisticated phases consider the length/complexity of the word before applying a rule. For example:
import nltk
from nltk.stem.porter import *
p_stemmer = PorterStemmer()
words = ['run','runner','running','ran','runs','easily','fairly']
for word in words:
print(word+' ---> '+p_stemmer.stem(word))
This is somewhat of a misnomer, as Snowball is the name of a stemming language developed by Martin Porter. The algorithm used here is more acurately called the "English Stemmer" or "Porter2 Stemmer". It offers a slight improvement over the original Porter stemmer, both in logic and speed. Since nltk uses the name SnowballStemmer, we'll use it here.
from nltk.stem.snowball import SnowballStemmer
# The Snowball Stemmer requires that you pass a language parameter
s_stemmer = SnowballStemmer(language='english')
words = ['run','runner','running','ran','runs','easily','fairly']
# words = ['generous','generation','generously','generate']
for word in words:
print(word+' --> '+s_stemmer.stem(word))